FXWizard
Гуру форума
Числовое представление паттернов. Необычный ракурс.
Не один год и не один раз у меня возникало желание создать базу паттернов по графикам цен с накоплением наиболее встречающихся комбинаций, чтобы под рукой иметь возможность зрительно идентифицировать отрезок графика реальных торгов, сравнить с уже известными и решить, что дальше делать. Всегда хочется немного заглянуть в будущее и хотя бы выбрать наиболее вероятный сценарий.
Варианты накапливались, находились подобные паттерны, но посчитать вероятность дорисовки графика так и не представлялось возможным. С одной стороны куски похожи то на букву N, то на М, W, И, с другой стороны все эти фигуры сильно размыты и растянуты, и подобие возникает в глазах трейдера после субъективного умозрительного представления. Казалось бы фракталы дают некоторое решение данной задачи, но пусть уж они остаются сами по себе, а я сделаю подборку паттернов несколько с другой стороны.
Некоторое время назад я решил, что неплохо было бы классифицировать паттерны немного попроще, но чтобы все вписывалось в некий достаточно ограниченный справочник, имело бы классификацию и ключи-идентификаторы, по которым можно было бы быстро найти паттерн. За одним хотелось бы получить ответ на вопрос о существовании стандартных ловушек Кукла, и что поспособствовало бы созданию небольшой такой аккуратненькой Базы Ловушек и финтов.
Неплохо было бы иметь такой инструмент или индикатор, который бы в любой момент времени с большей долей вероятности подсказывал направление, куда двинет рынок и какая фигура будет сформирована окончательно. Но чтобы это был не мой субъективный и интуитивный взгляд, а чтобы вероятность развития события использовать в МТС.
Для моих целей мне достаточно было бы идентифицировать весь график через непрерывно меняющиеся фигурки, а потом с помощью преобразования занести их в базу. На момент тестирования у меня имелись три месяца минутных данных по РИ, на них я и решил провести первый анализ.
Если же перевести все на график линий, то я представил себе данные ломаной линией через отрезки определенной длины (те же «кирпичики» Ренко). Для простоты и удобства восприятия я выбрал отрезки по 1000 пунктов РИ.
То есть весь поток данных можно представить в виде столбцов как в крестиках-ноликах, разница лишь в том, что разворотный коэффициент здесь равен 1 и проводить анализ легче на цифрах.
Преобразуем наши данные в ХО столбцы. И сожмем очень длинные столбцы до трех единиц. Ниже объясню почему мне понадобилось сжатие, Примерно это выглядит так на РИС_1:

Можно заметить, что это преобразование не из Крестиков-ноликов, хотя много общего с ними.
Не сомневаюсь, что у каждого из вас будет свой взгляд и свое видение по формированию ломаной, я же представлю результаты своего анализа, и считаю, что мой анализ достаточно неплохо отражает общую картину.
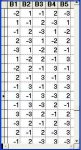
Этот же график занесем в базу в числовых кодах, но уже с преобразованием в группы по 5 столбцов. Это будет выглядеть вот так:

РИС_2
Вот как раз что мне и нужно, а график ХО нужен для визуальности.
Моим первым разочарованием при прогоне данных был тот факт, что из 200 строк (это и есть набор паттернов) по пять столбцов (B1,B2,B3,B4,B5) только пять строк встретились дважды за три месяца. Это вообще ни о чем! Это никакой вероятности, когда комбинации встречается по разу! Это означало то, что данных было недостаточно, а число отрезков (столбцов B) для идентификации паттерна завышено.
Необходимо было для анализа уменьшить число столбцов “B” в паттерне с первоначальных 5 столбцов до 4, прогнать данные за 6 лет, с разным масштабом по размеру кирпичика, по максимальной длине столбца, и ввести параметр смещения. Пришлось сжать длинные столбцы до трех кирпичиков (значения от -3 до +3) чтобы уменьшить число всевозможных комбинаций, которые растут в геометрической прогрессии с учетом того, что длина столбца может превысить и 15 и 20 кирпичиков и такая комбинация встретится может быть единственный раз за много лет.
Также нужно было определиться и с округлениями до целого отрезка, когда считать отрезок завершенным. И в этом вопросе каждый волен округлять или не округлять по собственным правилам. В классических крестиках-ноликах весь шум одиночных кирпичиков игнорируется, поэтому теряется вся суть, ради чего и велось исследование. За правило завершения отрезка я выбрал 95% от всего отрезка, а перегибом в обратную сторону только в случае прохождения полного отрезка на 100%. Сделано это было намеренно, чтобы паттерн и был похож сам на себя в графическом виде, состоящем из свечей. Необязательно ждать пробоя кирпичом. Неполный откат классически пусть остается в рамках прежнего столбца.
Если бы мы взяли комбинации из 4-5 столбцов с большим количеством кирпичиков, то множество таких фигурок просто встретилось бы один раз за много лет, но это уже другой, более детальный анализ, для решения других вопросов.
Таким образом, я рассматривал только 162 фигурки (комбинации) со значениями от -3 до 3 на четырех столбцах. Всего получается 3*3*3*3=81 и плюс обратные симметричные фигурки. Этого необходимо и достаточно для анализа.
На следующем рисунке представлены комбинации.

Рис_3
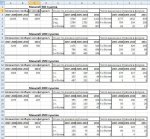
В таблице попарно представлены результаты 2007-2008,2009-2010, отдельно за 2011. Суммарные результаты за весь период можно сложить.
Пару 2005-2006 удалил как не представляющую особого интереса, она ничем не отличается от общей картины, только что данных там чуть поменьше. Эта пара интересна только в общем наборе за 6 лет.
Что размещено в таблице по строкам и столбцам. В этом анализе используются все 5 столбцов “B”
«Количество столбцов=кол. фигурок+5» (столбцы XO или строки из рисунка_2). Их на 5 больше за счет того, что первая фигура создается как минимум из 5 столбцов.
Столбцы "Из них по длине". Это количество единичных, двойных , тройных (и более) столбцов ХО за два года на графике ХО.
"Число единичных в фигурке". Фигурки для этого анализа содержат пять столбцов. Количество единичных в такой фигурке ( 3, 4, или все 5 единичные).
Например, число 2777 с масштабом 500 в 2007-2008 году означает, что 2777 фигурок (по 5 столбцов) имеют в себе как минимум три единичных кирпичика. 704 - как минимум 4 единичных кирпичика из пяти.
Интуитивно понятно, что единичных кирпичиков больше, двойных меньше, тройных еще меньше и так далее. Можно заметить, что одинарных кирпичиков на всех масштабах и на всех периодах времени меньше половины (примерно от 37% до 44%), но больше чем всех других отдельно взятых. Не думаю, что рынок так сам себя специально распределяет совсем уж случайным образом. Как говорил Винни Пух: «Это Ж-Ж-Ж-Ж не спроста…» . Я не привел данные по 3000, 4000, 5000, потому что картина получается такая же, но данных там меньше, поэтому и разброс может быть побольше. Что влияет на такое распределение невозможно сказать, но то, что это совсем не случайно, показывают результаты за 6 лет.
Какие можно сделать выводы?
1.Тесты показывают, что нельзя просто перейти на усреднение и мартингейл, хотя вроде бы если брать единичные и парные кирпичики, кажется что вроде бы даже неплохо, ведь их число намного больше всех 3-к. То есть предпосылки к тому есть, и люди интуитивно чувствуют их, на чем и попадаются. И это нужно иметь ввиду тем, кто будет строить стратегию на мартингейле. Дело в том, что при мартингейле слишком быстро происходит наращивание позиции и всегда надо начинать с маленьких сумм ради небольшой прибыли. И уже на 5 кирпичиках увеличения надо наращивать позицию в 32 раза больше изначальной. Безоткатные движения могут достигать более 15 кирпичиков в столбце. Это самоубийство работать на стратегии усреднения.
И все же есть стратегии на основе "скальпирования" отрезков без усреднения. Нужно знать, когда резать лося. Можно строить стратегию скальпирования на концах отрезков без усреднения, но здесь приходится обходить немало подводных камней.
2. Трендовые стратегии. Здесь нужно учитывать распилы на единичных и парных отрезках. Напилить может на любом масштабе. Табличка со статистикой по продолжительности серии единичных отрезков приведена в конце статьи.
Отдельно можно упомянуть Ренко. Хорошая игра, но ее недостаток в том, что она распиливает двойки. Да, единичные отрезки Ренко не видит и воспринимает как шум, но нечастые двойки временами сильно достают. Если же брать тройки (разворотный коэфф.=3), то система слишком поздно обнаруживает разворот, а обратное движение может сильно испортить картину. Так чего же больше, пил или трендов? Статистика показывает, что тренды могут неплохо пилиться, а пилы нередко порождают безоткатный тренд.
Сейчас о смещениях. Что будет, если масштаб поменять и брать 600,700,1135 и вообще сколько угодно пунктов, или как в Ренко сделать смещение динамическим. Что будет, если изменить начальную отправную цену? Анализ показывает, что все в рамках прежней статистики.
Конечно, смещение влияет на результаты и на статистику, на одном масштабе в течение определенного времени при смещении будет другая статистика. Будет больше или меньше единичных, двойных отрезков, изменится соотношение паттернов. В классическом ТА невозможно заранее узнать, настоящий пробой или ложный. И здесь по сути, в моем представлений то же самое. Если идентифицировать паттерн по первым трем кирпичикам, узнать какой будет хвост с долей вероятности возможно. Но пока непонятно, как реализовать в тестере. Хотелось бы конечно попробовать, и это будет уже другая история.
Предполагал, что составлю справочник паттернов с весом на каждом масштабе, но поскольку он на разных масштабах все же отличается, не буду этим забивать и себе и вам голову. В общих словах можно сказать.
Самый частый или почти самый частый числовой паттерн, как можно догадаться 1,-1,1,-1 (ХОХО) и его отражение (ОХОХ). Это практически на любом масштабе, в любое время при любом смещении. Только это ничего не дает, так как близкие к нему по содержанию паттерны встречаются столько же раз, а бывает и больше. То есть отрезки /\/\ или \/\/ в любом масштабе частое явление, но выход неоднозначен.
То же самое можно сказать про флэты и флаги /\/\/ и про \/\/\.
Довольно часто встречаются паттерны, состоящие из трех единичных отрезков и одного тройного, где 3 все что больше равно 3 кирпичиков.
Наиболее редкие четыре двойки. Но как же так. Ведь двойка для 500, это единичный для 1000, а двойка для 1000, это единичный для 2000. Но 1000-му вообще наплевать на движения и шум внутри себя. Он не видит смещения 500-ок. Двойка для 500 может уйти в единичный 1000 и присуммироваться к нему, но вот обратное утверждение неверно. Далеко не каждый единичный 1000 станет обязательно двойным для 500.
Еще интересно. РИ был и по 80000 и по 230000, был примечательный во всех отношениях 2008 год. Неужели распределение везде одинаковое?
Приведу статистику и результаты подряд встречающихся единичных отрезков на масштабах 1000,2000,3000,5000. Отдельно по 2008 году и отдельно по всем остальным.
В скобочках масштаб. Первая цифра - количество подряд идущих единичных отрезков. Вторая цифра - сколько раз встречалось за период.
2005,2006,2007,2009,2010,2011 г.
Код:
(1000) (2000) (3000) (5000)
9 - 14 9 - 4 7 - 10 6 - 7
10 - 14 8 - 3 8 - 1
11 - 8 11 -1
12 - 5
13 - 3
14 - 1
15 - 1
2008
Код:
(1000) (2000) (3000) (5000)
9 - 15 9 - 4 7 - 4 7 - 3
10 - 5 10 - 4 8 - 4 8 - 1
11 - 4 11 - 1 9 - 1 9 - 2
12 - 2 12 - 1 10- 3
13 - 2
15 - 1 15 - 1
16 - 2
17 - 1
18 - 1
В своей статье я хотел с вами поделиться своими тестами и не преследовал цели навязать свои выводы.
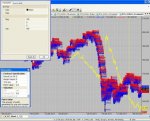
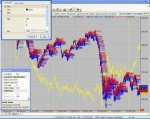
Наверное стоит показать результаты тестирования по методу Ренко с коэффициентом разворота=1 за период с 29.03.2011. Проскальзывание 100 пунктов несколько завышено. По этим тестам видно, что основная проблема при такой технике, это проскальзывание. Графики представил просто как приложение к теме, выводы делайте сами. Подгонкой лучше не заниматься, так что и эта статистика укладывается в рамки рассмотренной темы. Как подключить справочник паттернов для улучшения эквити, пока непонятно.

Рисунок АМИ_500

Рисунок АМИ_1000

Рисунок АМИ_2000

Рисунок АМИ_4000
Автор: Сергей Григорьев
_www.russian-trader.ru
Не один год и не один раз у меня возникало желание создать базу паттернов по графикам цен с накоплением наиболее встречающихся комбинаций, чтобы под рукой иметь возможность зрительно идентифицировать отрезок графика реальных торгов, сравнить с уже известными и решить, что дальше делать. Всегда хочется немного заглянуть в будущее и хотя бы выбрать наиболее вероятный сценарий.
Варианты накапливались, находились подобные паттерны, но посчитать вероятность дорисовки графика так и не представлялось возможным. С одной стороны куски похожи то на букву N, то на М, W, И, с другой стороны все эти фигуры сильно размыты и растянуты, и подобие возникает в глазах трейдера после субъективного умозрительного представления. Казалось бы фракталы дают некоторое решение данной задачи, но пусть уж они остаются сами по себе, а я сделаю подборку паттернов несколько с другой стороны.
Некоторое время назад я решил, что неплохо было бы классифицировать паттерны немного попроще, но чтобы все вписывалось в некий достаточно ограниченный справочник, имело бы классификацию и ключи-идентификаторы, по которым можно было бы быстро найти паттерн. За одним хотелось бы получить ответ на вопрос о существовании стандартных ловушек Кукла, и что поспособствовало бы созданию небольшой такой аккуратненькой Базы Ловушек и финтов.
Неплохо было бы иметь такой инструмент или индикатор, который бы в любой момент времени с большей долей вероятности подсказывал направление, куда двинет рынок и какая фигура будет сформирована окончательно. Но чтобы это был не мой субъективный и интуитивный взгляд, а чтобы вероятность развития события использовать в МТС.
Для моих целей мне достаточно было бы идентифицировать весь график через непрерывно меняющиеся фигурки, а потом с помощью преобразования занести их в базу. На момент тестирования у меня имелись три месяца минутных данных по РИ, на них я и решил провести первый анализ.
Если же перевести все на график линий, то я представил себе данные ломаной линией через отрезки определенной длины (те же «кирпичики» Ренко). Для простоты и удобства восприятия я выбрал отрезки по 1000 пунктов РИ.
То есть весь поток данных можно представить в виде столбцов как в крестиках-ноликах, разница лишь в том, что разворотный коэффициент здесь равен 1 и проводить анализ легче на цифрах.
Преобразуем наши данные в ХО столбцы. И сожмем очень длинные столбцы до трех единиц. Ниже объясню почему мне понадобилось сжатие, Примерно это выглядит так на РИС_1:
Можно заметить, что это преобразование не из Крестиков-ноликов, хотя много общего с ними.
Не сомневаюсь, что у каждого из вас будет свой взгляд и свое видение по формированию ломаной, я же представлю результаты своего анализа, и считаю, что мой анализ достаточно неплохо отражает общую картину.
Этот же график занесем в базу в числовых кодах, но уже с преобразованием в группы по 5 столбцов. Это будет выглядеть вот так:
РИС_2
Вот как раз что мне и нужно, а график ХО нужен для визуальности.
Моим первым разочарованием при прогоне данных был тот факт, что из 200 строк (это и есть набор паттернов) по пять столбцов (B1,B2,B3,B4,B5) только пять строк встретились дважды за три месяца. Это вообще ни о чем! Это никакой вероятности, когда комбинации встречается по разу! Это означало то, что данных было недостаточно, а число отрезков (столбцов B) для идентификации паттерна завышено.
Необходимо было для анализа уменьшить число столбцов “B” в паттерне с первоначальных 5 столбцов до 4, прогнать данные за 6 лет, с разным масштабом по размеру кирпичика, по максимальной длине столбца, и ввести параметр смещения. Пришлось сжать длинные столбцы до трех кирпичиков (значения от -3 до +3) чтобы уменьшить число всевозможных комбинаций, которые растут в геометрической прогрессии с учетом того, что длина столбца может превысить и 15 и 20 кирпичиков и такая комбинация встретится может быть единственный раз за много лет.
Также нужно было определиться и с округлениями до целого отрезка, когда считать отрезок завершенным. И в этом вопросе каждый волен округлять или не округлять по собственным правилам. В классических крестиках-ноликах весь шум одиночных кирпичиков игнорируется, поэтому теряется вся суть, ради чего и велось исследование. За правило завершения отрезка я выбрал 95% от всего отрезка, а перегибом в обратную сторону только в случае прохождения полного отрезка на 100%. Сделано это было намеренно, чтобы паттерн и был похож сам на себя в графическом виде, состоящем из свечей. Необязательно ждать пробоя кирпичом. Неполный откат классически пусть остается в рамках прежнего столбца.
Если бы мы взяли комбинации из 4-5 столбцов с большим количеством кирпичиков, то множество таких фигурок просто встретилось бы один раз за много лет, но это уже другой, более детальный анализ, для решения других вопросов.
Таким образом, я рассматривал только 162 фигурки (комбинации) со значениями от -3 до 3 на четырех столбцах. Всего получается 3*3*3*3=81 и плюс обратные симметричные фигурки. Этого необходимо и достаточно для анализа.
На следующем рисунке представлены комбинации.
Рис_3
В таблице попарно представлены результаты 2007-2008,2009-2010, отдельно за 2011. Суммарные результаты за весь период можно сложить.
Пару 2005-2006 удалил как не представляющую особого интереса, она ничем не отличается от общей картины, только что данных там чуть поменьше. Эта пара интересна только в общем наборе за 6 лет.
Что размещено в таблице по строкам и столбцам. В этом анализе используются все 5 столбцов “B”
«Количество столбцов=кол. фигурок+5» (столбцы XO или строки из рисунка_2). Их на 5 больше за счет того, что первая фигура создается как минимум из 5 столбцов.
Столбцы "Из них по длине". Это количество единичных, двойных , тройных (и более) столбцов ХО за два года на графике ХО.
"Число единичных в фигурке". Фигурки для этого анализа содержат пять столбцов. Количество единичных в такой фигурке ( 3, 4, или все 5 единичные).
Например, число 2777 с масштабом 500 в 2007-2008 году означает, что 2777 фигурок (по 5 столбцов) имеют в себе как минимум три единичных кирпичика. 704 - как минимум 4 единичных кирпичика из пяти.
Интуитивно понятно, что единичных кирпичиков больше, двойных меньше, тройных еще меньше и так далее. Можно заметить, что одинарных кирпичиков на всех масштабах и на всех периодах времени меньше половины (примерно от 37% до 44%), но больше чем всех других отдельно взятых. Не думаю, что рынок так сам себя специально распределяет совсем уж случайным образом. Как говорил Винни Пух: «Это Ж-Ж-Ж-Ж не спроста…» . Я не привел данные по 3000, 4000, 5000, потому что картина получается такая же, но данных там меньше, поэтому и разброс может быть побольше. Что влияет на такое распределение невозможно сказать, но то, что это совсем не случайно, показывают результаты за 6 лет.
Какие можно сделать выводы?
1.Тесты показывают, что нельзя просто перейти на усреднение и мартингейл, хотя вроде бы если брать единичные и парные кирпичики, кажется что вроде бы даже неплохо, ведь их число намного больше всех 3-к. То есть предпосылки к тому есть, и люди интуитивно чувствуют их, на чем и попадаются. И это нужно иметь ввиду тем, кто будет строить стратегию на мартингейле. Дело в том, что при мартингейле слишком быстро происходит наращивание позиции и всегда надо начинать с маленьких сумм ради небольшой прибыли. И уже на 5 кирпичиках увеличения надо наращивать позицию в 32 раза больше изначальной. Безоткатные движения могут достигать более 15 кирпичиков в столбце. Это самоубийство работать на стратегии усреднения.
И все же есть стратегии на основе "скальпирования" отрезков без усреднения. Нужно знать, когда резать лося. Можно строить стратегию скальпирования на концах отрезков без усреднения, но здесь приходится обходить немало подводных камней.
2. Трендовые стратегии. Здесь нужно учитывать распилы на единичных и парных отрезках. Напилить может на любом масштабе. Табличка со статистикой по продолжительности серии единичных отрезков приведена в конце статьи.
Отдельно можно упомянуть Ренко. Хорошая игра, но ее недостаток в том, что она распиливает двойки. Да, единичные отрезки Ренко не видит и воспринимает как шум, но нечастые двойки временами сильно достают. Если же брать тройки (разворотный коэфф.=3), то система слишком поздно обнаруживает разворот, а обратное движение может сильно испортить картину. Так чего же больше, пил или трендов? Статистика показывает, что тренды могут неплохо пилиться, а пилы нередко порождают безоткатный тренд.
Сейчас о смещениях. Что будет, если масштаб поменять и брать 600,700,1135 и вообще сколько угодно пунктов, или как в Ренко сделать смещение динамическим. Что будет, если изменить начальную отправную цену? Анализ показывает, что все в рамках прежней статистики.
Конечно, смещение влияет на результаты и на статистику, на одном масштабе в течение определенного времени при смещении будет другая статистика. Будет больше или меньше единичных, двойных отрезков, изменится соотношение паттернов. В классическом ТА невозможно заранее узнать, настоящий пробой или ложный. И здесь по сути, в моем представлений то же самое. Если идентифицировать паттерн по первым трем кирпичикам, узнать какой будет хвост с долей вероятности возможно. Но пока непонятно, как реализовать в тестере. Хотелось бы конечно попробовать, и это будет уже другая история.
Предполагал, что составлю справочник паттернов с весом на каждом масштабе, но поскольку он на разных масштабах все же отличается, не буду этим забивать и себе и вам голову. В общих словах можно сказать.
Самый частый или почти самый частый числовой паттерн, как можно догадаться 1,-1,1,-1 (ХОХО) и его отражение (ОХОХ). Это практически на любом масштабе, в любое время при любом смещении. Только это ничего не дает, так как близкие к нему по содержанию паттерны встречаются столько же раз, а бывает и больше. То есть отрезки /\/\ или \/\/ в любом масштабе частое явление, но выход неоднозначен.
То же самое можно сказать про флэты и флаги /\/\/ и про \/\/\.
Довольно часто встречаются паттерны, состоящие из трех единичных отрезков и одного тройного, где 3 все что больше равно 3 кирпичиков.
Наиболее редкие четыре двойки. Но как же так. Ведь двойка для 500, это единичный для 1000, а двойка для 1000, это единичный для 2000. Но 1000-му вообще наплевать на движения и шум внутри себя. Он не видит смещения 500-ок. Двойка для 500 может уйти в единичный 1000 и присуммироваться к нему, но вот обратное утверждение неверно. Далеко не каждый единичный 1000 станет обязательно двойным для 500.
Еще интересно. РИ был и по 80000 и по 230000, был примечательный во всех отношениях 2008 год. Неужели распределение везде одинаковое?
Приведу статистику и результаты подряд встречающихся единичных отрезков на масштабах 1000,2000,3000,5000. Отдельно по 2008 году и отдельно по всем остальным.
В скобочках масштаб. Первая цифра - количество подряд идущих единичных отрезков. Вторая цифра - сколько раз встречалось за период.
2005,2006,2007,2009,2010,2011 г.
Код:
(1000) (2000) (3000) (5000)
9 - 14 9 - 4 7 - 10 6 - 7
10 - 14 8 - 3 8 - 1
11 - 8 11 -1
12 - 5
13 - 3
14 - 1
15 - 1
2008
Код:
(1000) (2000) (3000) (5000)
9 - 15 9 - 4 7 - 4 7 - 3
10 - 5 10 - 4 8 - 4 8 - 1
11 - 4 11 - 1 9 - 1 9 - 2
12 - 2 12 - 1 10- 3
13 - 2
15 - 1 15 - 1
16 - 2
17 - 1
18 - 1
В своей статье я хотел с вами поделиться своими тестами и не преследовал цели навязать свои выводы.
Наверное стоит показать результаты тестирования по методу Ренко с коэффициентом разворота=1 за период с 29.03.2011. Проскальзывание 100 пунктов несколько завышено. По этим тестам видно, что основная проблема при такой технике, это проскальзывание. Графики представил просто как приложение к теме, выводы делайте сами. Подгонкой лучше не заниматься, так что и эта статистика укладывается в рамки рассмотренной темы. Как подключить справочник паттернов для улучшения эквити, пока непонятно.
Рисунок АМИ_500
Рисунок АМИ_1000
Рисунок АМИ_2000
Рисунок АМИ_4000
Автор: Сергей Григорьев
_www.russian-trader.ru