cfifcfif
Элитный участник
Программинг микроконтроллеров*, Высокая производительность*
Данная статья рассказывает о разработке узкоспециализированного аппаратного устройства для целей HFT. Его специализация направлена на достижение минимально возможных временных задержек для обработки рыночных данных и, следовательно, на уменьшение времени раунд-трипа при осуществлении сделок. Реализация, описанная в этой работе, осуществляет разбор пакетов Ethernet, IP и UDP, а также FAST протокола, который является наиболее распространенным при передаче рыночной информации. Для подобных целей был разработан собственный движок микрокода, с поддержкой набора команд и компилятором, благодаря чему достигается поддержка широкого круга применяемых в трейдинге протоколов. Конечная система была реализована в RTL коде и исполняется на FPGA. Данный подход показывает преимущество в 4 раза, по сравнению с полностью программными решениями.
Введение
Высокочастотному трейдингу (HFT) уделяется большое внимание в последнее время, и он становится важнейшим игроком на финансовых рынках. Под термином HFT понимается набор техник при торговле акциями и деривативами, когда большой поток заявок отправляется на рынок с раунд-трипом меньше миллисекунды[1]. Цель высокочастотников, это подойди к концу дня без каких-либо позиций ценных бумаг в наличии, а получать прибыль от своих стратегий покупая и продавая акции на очень высокой скорости. Исследования показывают, что HFT трейдеры держат акцию в среднем всего 22 секунды[2]. Aite Group утверждает, что HFT оказывает существенное влияние на рынок, более чем 50% сделок по акциям в США было совершенно HFT в 2010 году, при этом рост только за 2009 год составил 70%[3].
HFT трейдеры используют несколько вариантов стратегий, как например — стратегия по обеспечению ликвидности, стратегия статистического арбитража и стратегия по поиску ликвидности [2]. В стратегии по обеспечению ликвидности, высокочастотники пытаются заработать на спреде спроса-предложения(bid-ask), который отражает разницу, по которой продавцы готовы продать, а покупатели купить. Высокая волатильность и широкий bid-ask спред могут обернуться прибылью для HFT трейдера, и в то же время он становится поставщиком ликвидности и сужает bid-ask спред, как бы исполняя роль маркетмейкера. Ликвидность и маленький ask-bid спред являются важными вещами, поскольку они снижают торговые издержки и позволяют точнее определить стоимость актива[4]. Трейдеры, которые используют арбитражные стратегии, используют корреляцию между ценами производных инструментов и их базовых активов[5]. Стратегии по поиску ликвидности исследуют рынок в поисках крупных заявок, путем посылки небольших приказов, которые помогают обнаружить большие скрытые заявки. Все стратегии объединяет одно, для работы им требуются бескомпромиссно низкие временные задержки, поскольку только самые быстрые HFT компании в состоянии воспользоваться возникающими на рынке возможностями.
Электронная торговля акциями происходит путем посылки запросов в электронной форме на биржу. Заявки на покупку и продажу затем сопоставляются на бирже, и осуществляется сделка. Выставляемые заявки видны всем участникам торгов через так называемые фиды. Фид – это сжатый или несжатый поток данных, поставляемый в реальном времени некой независимой организацией, как например Options Price Reporting Authority (OPRA). Фид содержит финансовую информацию по акциям и передается с помощью мультикаста участникам рынка через стандартизированные протоколы, в основном через Ethernet посредством UDP. Стандартным протоколом поставки рыночных данных является Financial Information Exchange (FIX) Adapted for Streaming (FAST), который используется на большинстве бирж[18].
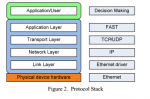
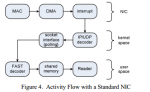
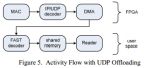
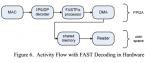
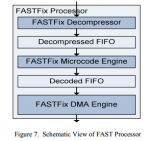
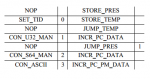
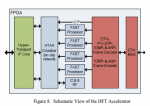
Для того чтобы добиться минимального времени задержки, HFT движок должен быть оптимизирован на всех уровнях. Для уменьшения времени задержки при передачи по сети используется collocation, когда HFT сервер устанавливается рядом со шлюзом биржи. Фид с данными должен распространятся с минимальными задержками до серверов HFT. Эффективная обработка UDP и FAST пакетов также является необходимой. И наконец, решение о создании заявки и ее передача должны осуществляется с наименьшими возможными задержками. Для достижения этих целей был разработан новый HFT движок, реализованный на плате FPGA. Благодаря использованию FPGA, появилась возможность снять нагрузку по обработке UDP и FAST с центрального процессора и перенести ее на специально оптимизированные блоки платы. В представленной системе, на аппаратном уровне реализован весь цикл обработки, за исключением принятий торговых решений, включая крайне гибкий движок с поддержкой микрокода для обработки FAST сообщений. Подход дает значительное снижение задержек более чем на 70% по сравнению с софтверными решениями и в то же время позволяет гораздо проще изменять или добавлять обработку новых протоколов, чем интегральные схемы специального назначения(Application-specific integrated circuit).
История вопроса
Текущий раздел рассказывает о базовых концепциях и реализации биржевой инфраструктуры. В дополнение, будет рассказано о базовых свойствах протокола FAST, чтобы определить требования к аппаратной реализации.
Инфраструктура для трейдинга
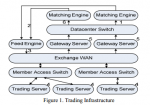
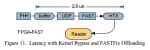
Типичная инфраструктура для трейдинга состоит из нескольких компонентов, контролируемых различными участниками. Это – биржа, поставщик фида и участники рынка, как показано на Figure 1. Движок для сопоставления заявок (матчинга), маршрутизатор дата-центра, и шлюз контролируются биржей. Механизм для фидов предоставляет другая организация. Маршрутизатор для доступа участников рынка – это собственность этих участников, в данном случае HFT фирм.
Данная статья рассказывает о разработке узкоспециализированного аппаратного устройства для целей HFT. Его специализация направлена на достижение минимально возможных временных задержек для обработки рыночных данных и, следовательно, на уменьшение времени раунд-трипа при осуществлении сделок. Реализация, описанная в этой работе, осуществляет разбор пакетов Ethernet, IP и UDP, а также FAST протокола, который является наиболее распространенным при передаче рыночной информации. Для подобных целей был разработан собственный движок микрокода, с поддержкой набора команд и компилятором, благодаря чему достигается поддержка широкого круга применяемых в трейдинге протоколов. Конечная система была реализована в RTL коде и исполняется на FPGA. Данный подход показывает преимущество в 4 раза, по сравнению с полностью программными решениями.
Введение
Высокочастотному трейдингу (HFT) уделяется большое внимание в последнее время, и он становится важнейшим игроком на финансовых рынках. Под термином HFT понимается набор техник при торговле акциями и деривативами, когда большой поток заявок отправляется на рынок с раунд-трипом меньше миллисекунды[1]. Цель высокочастотников, это подойди к концу дня без каких-либо позиций ценных бумаг в наличии, а получать прибыль от своих стратегий покупая и продавая акции на очень высокой скорости. Исследования показывают, что HFT трейдеры держат акцию в среднем всего 22 секунды[2]. Aite Group утверждает, что HFT оказывает существенное влияние на рынок, более чем 50% сделок по акциям в США было совершенно HFT в 2010 году, при этом рост только за 2009 год составил 70%[3].
HFT трейдеры используют несколько вариантов стратегий, как например — стратегия по обеспечению ликвидности, стратегия статистического арбитража и стратегия по поиску ликвидности [2]. В стратегии по обеспечению ликвидности, высокочастотники пытаются заработать на спреде спроса-предложения(bid-ask), который отражает разницу, по которой продавцы готовы продать, а покупатели купить. Высокая волатильность и широкий bid-ask спред могут обернуться прибылью для HFT трейдера, и в то же время он становится поставщиком ликвидности и сужает bid-ask спред, как бы исполняя роль маркетмейкера. Ликвидность и маленький ask-bid спред являются важными вещами, поскольку они снижают торговые издержки и позволяют точнее определить стоимость актива[4]. Трейдеры, которые используют арбитражные стратегии, используют корреляцию между ценами производных инструментов и их базовых активов[5]. Стратегии по поиску ликвидности исследуют рынок в поисках крупных заявок, путем посылки небольших приказов, которые помогают обнаружить большие скрытые заявки. Все стратегии объединяет одно, для работы им требуются бескомпромиссно низкие временные задержки, поскольку только самые быстрые HFT компании в состоянии воспользоваться возникающими на рынке возможностями.
Электронная торговля акциями происходит путем посылки запросов в электронной форме на биржу. Заявки на покупку и продажу затем сопоставляются на бирже, и осуществляется сделка. Выставляемые заявки видны всем участникам торгов через так называемые фиды. Фид – это сжатый или несжатый поток данных, поставляемый в реальном времени некой независимой организацией, как например Options Price Reporting Authority (OPRA). Фид содержит финансовую информацию по акциям и передается с помощью мультикаста участникам рынка через стандартизированные протоколы, в основном через Ethernet посредством UDP. Стандартным протоколом поставки рыночных данных является Financial Information Exchange (FIX) Adapted for Streaming (FAST), который используется на большинстве бирж[18].
Для того чтобы добиться минимального времени задержки, HFT движок должен быть оптимизирован на всех уровнях. Для уменьшения времени задержки при передачи по сети используется collocation, когда HFT сервер устанавливается рядом со шлюзом биржи. Фид с данными должен распространятся с минимальными задержками до серверов HFT. Эффективная обработка UDP и FAST пакетов также является необходимой. И наконец, решение о создании заявки и ее передача должны осуществляется с наименьшими возможными задержками. Для достижения этих целей был разработан новый HFT движок, реализованный на плате FPGA. Благодаря использованию FPGA, появилась возможность снять нагрузку по обработке UDP и FAST с центрального процессора и перенести ее на специально оптимизированные блоки платы. В представленной системе, на аппаратном уровне реализован весь цикл обработки, за исключением принятий торговых решений, включая крайне гибкий движок с поддержкой микрокода для обработки FAST сообщений. Подход дает значительное снижение задержек более чем на 70% по сравнению с софтверными решениями и в то же время позволяет гораздо проще изменять или добавлять обработку новых протоколов, чем интегральные схемы специального назначения(Application-specific integrated circuit).
История вопроса
Текущий раздел рассказывает о базовых концепциях и реализации биржевой инфраструктуры. В дополнение, будет рассказано о базовых свойствах протокола FAST, чтобы определить требования к аппаратной реализации.
Инфраструктура для трейдинга
Типичная инфраструктура для трейдинга состоит из нескольких компонентов, контролируемых различными участниками. Это – биржа, поставщик фида и участники рынка, как показано на Figure 1. Движок для сопоставления заявок (матчинга), маршрутизатор дата-центра, и шлюз контролируются биржей. Механизм для фидов предоставляет другая организация. Маршрутизатор для доступа участников рынка – это собственность этих участников, в данном случае HFT фирм.