FXWizard
Гуру форума
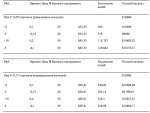
Приведение оптимального f к текущим ценам
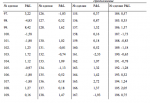
Оптимальное f даст наибольший геометрический рост при большом количестве сделок. Это математический факт. Рассмотрим гипотетический поток сделок:
+3, -3, +10, -5
Из этого потока сделок мы найдем, что оптимальное f= 0,17 (ставка 1 единицы на каждые 29,41 доллара на балансе). Такой подход при данном потоке даст нам наи-больший рост счета.
Представьте себе, что этот поток выражает прибыли и убытки при торговле одной акцией. Оптимально следует покупать одну акцию на каждые 29,41 доллара на балансе счета, несмотря на текущую цену акции. Предположим, что текущая цена акции равна 100 долларам. Более того, допустим, что при первых двух сделках акция стоила 20 долларов, а при двух последних сделках — 50 долларов.
Для наших первых двух сделок, которые произошли при цене акции в 20 долларов, выигрыш в 2 доллара соответствует выигрышу в 10%, а проигрыш 3 долларов соответствует проигрышу в 15%. Для двух последних сделок при цене акции 50 долларов выигрыш 10 долларов соответствует выигрышу в 20%, а проигрыш в 5 долларов соответствует проигрышу в 10%.
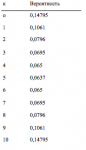
1 Разумный подход требует, чтобы мы использовали наибольший проигрыш, по крайней мере, такой же величины, как и в прошлом. С течением времени мы получаем все большее количество данных и большие периоды проигрышей. Например, если бросить монету 100 раз, она может 12 раз подряд выпасть на обратную сторону. Если бросить ее 1000 раз, то, вероятно, можно получить еще больший период, когда монета выпадет обратной стороной. Тот же принцип работает и в торговле. Мы не только должны ожидать более длинные полосы проигрышных сделок в будущем, следует также ожидать большую проигрышную сделку наихудшего случая.

Формулы преобразования необработанных торговых P&L в процент выигрыша и проигрыша для длинных и коротких позиций следующие:
(2. 10а) P&L% = Цена выхода / Цена входа — 1 (для длинных)
(2.106) , P&L% = Цена входа / Цена выхода - 1 (для коротких),
или мы можем использовать следующую формулу для преобразования как длин- ных, так и коротких:
(2.10в) P&L% = P&L в пунктах / Цена входа
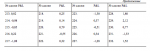
Таким образом, для наших 4 гипотетических сделок мы получим следующий поток процентных выигрышей и проигрышей (с точки зрения длинных позиций):
+0,1 ; -0,15 ; +0,2 ; -0,1
Мы назовем этот новый поток преобразованных P&L приведенными данными, так как при торговле они приводятся к цене базового инструмента.
Чтобы учесть комиссионные и проскальзывание, вы должны уменьшить цену выхода в уравнении (2.10а) на сумму комиссионных и проскальзывания. Таким же образом вам следует увеличить цену выхода в (2.106). Если вы используете (2.10в), то должны вычесть сумму комиссионных и проскальзывания (в пунктах) из числителя (P&L в пунктах). Затем мы определим оптимальное f по этим процентным выигрышам и проигрышам. Оптимальное f будет равно 0,09. Преобразуем это оптимальное f= 0,09 в денежный эквивалент, основываясь на текущей цене акции, с помощью формулы:
(2.11) f$ = Наибольший процентный проигрыш * Текущая цена * ($ за пункт/ -f)
Таким образом, так как наш наибольший процентный проигрыш был -0,15, теку- щая цена равна 100 долларам за акцию, а количество долларов на пункт равно 1 (так как мы имеем дело с покупкой только 1 акции), можно определить f$ следую- щим образом:
f$ =-0,15*100*1/-0,09 =-15/-0,09 = 166,67
Следует покупать 1 акцию на каждые 166,67 долларов баланса счета. Если бы мы выбрали 100 акций в качестве единицы, единственной переменной, затронутой этим изменением, было бы количество долларов за полный пункт, которое стало бы равно 100. В результате, f$ было бы 16 666,67 доллара баланса на каждые 100 акций.
Теперь допустим, что цена акции упала до 3 долларов. Наше уравнение для f$ будет таким же, но текущая станет равна 3. Таким образом, сумма для финансиро- вания 1 акции изменится:
f$=-0,15*3* 1/-0,09 = -0,45 / -0,09=5
Теперь следует покупать 1 акцию на каждые 5 долларов баланса счета.
Отметьте, что оптимальное f не изменяется с текущей ценой акции. Оно оста- ется на уровне 0,09. Однако f$ меняется постоянно, так как меняется цена акции. Это не означает, что вы должны обязательно изменить позицию, которую уже открыли в этот день, но если бы вы так поступили, то это пошло бы на пользу тор- говле. Например, если вы открываете длинную позицию по какой-либо акции и ее цена падает, количество денег, которое вам следует разместить под 1 единицу (100 акций в этом случае), также уменьшится (если оптимальное f получено из приведенньк данных). Если ваше оптимальное f получено из необработанных данных, то количество денег, необходимое для 1 единицы, не уменьшится. В обоих случаях ваш дневной баланс понижается. Использование приведенного оптимального f делает более вероятным, что ежедневное изменение размера позиции пойдет вам на пользу Использование приведенных данных для оптимального f неизбежно влечет за собой изменение побочных продуктов1. Мы знаем, что и оптимальное f, и среднее геометрическое (и отсюда TWR) изменятся. Средняя арифметическая сделка также изменится, потому что все сделки в прошлом должны быть пересчитаны, как если бы они происходили при текущей цене. Таким образом, в нашем предполагаемом потоке результатов по 1 акции (+2,-3,+10и-5) мы получим среднюю сделку, равную 1 доллару. Когда мы используем процентные выигрыши и проигрыши (+0,1; -0,15; +0,2 и -0,1), то получаем среднюю сделку (в процентах) +0,5. При цене 100 долларов за акцию мы получим среднюю сделку 100 * 0,05, или 5 долларов за сделку. При цене 3 доллара за акцию средняя сделка становится равной 0,15 доллара (3 * 0,05).
Средняя геометрическая сделка также изменится. Вспомните уравнение (1.14) для средней геометрической сделки:
(1.14) GAT = G * (Наибольший проигрыш /-f),
где G = (среднее геометрическое) -1;
f=оптимальная фиксированная доля. (Разумеется, наш наибольший проигрыш
всегда является отрицательным числом.) Это уравнение эквивалентно следующему:
GAT = (среднее геометрическое - 1) * f$
Мы получили новое среднее геометрическое на основе приведенных данных. Переменная f$, которая была постоянной, когда прошлые данные не приводились, теперь изменится, так как она является функцией текущей цены. Таким образом, наша средняя геометрическая сделка меняется, когда меняется цена базового инструмента.
Порог геометрической торговли также должен измениться. Вспомните уравнение (2.02) для порога геометрической торговли:

где Т = порог геометрической торговли;
ААТ = средняя арифметическая сделка;
GAT =средняя геометрическая сделка;
f= оптимальное f (от 0 до 1). Это уравнение также можно переписать
следующим образом:
Т = ААТ/GAT* f$
Наконец, при сведении в единый портфель нескольких рыночных систем мы дол- жны рассчитать ежедневные HPR. Это также функция f$:
1 Уравнения риска разорения, хотя они напрямую и не упомянуты в этой книге, должны также изменяться при использовании приведенных данных. Вообще в качестве вводных данных для уравнений риска разорения используют необработанные данные P&L. Однако когда вы используете приведенные данные, новый поток процентных выигрышей и проигрышей должен умножаться на текущую цену базового инструмента, и далее надо использовать именно этот получившийся поток. Таким образом, при текущей цене инструмента 100 долларов поток процентных выигрышей и проигрышей 0,1; -0,15; 0,2; -0,1 преобразуется в поток 10; -15; 20; -10. Этот новый поток и следует использовать для уравнений риска разорения.

(2.12) Дневное HPR = D$ / f$ + 1,
где D$ = долларовое изменение цены 1 единицы по сравнению с прошлым днем, т. е. (закрытие сегодня - закрытие вчера) * (доллары за пункт);
f$= текущее оптимальное f в долларах, рассчитанное из уравнения (2.11). Здесь текущей ценой является закрытие последнего дня.
Предположим, некая акция сегодня вечером закрылась на уровне 99 долларов. На прошлой сессии ее цена была 102 доллара. Наибольший процентный проигрыш равен -15. Если f= 0,09, тогда f$ равно:
f$ =-0,15*102*1/-0,09 =-15,3/-0,09 = 170
Так как мы имеем дело только с одной акцией, цена одного пункта составляет 1 доллар. Мы можем теперь определить сегодняшнее дневное HPR из уравнения (2.12):
(2.12) Дневное HPR = (99 -102) * 1 / 170 + 1 =-3/170+1 = -0,01764705882 + 1 = 0,9823529412
Теперь вернемся к началу нашей дискуссии. При потоке торговых P&L оптимальное f позволит получить наибольший геометрический рост (при условии, что арифметическое математическое ожидание положительное)'. Мы используем по- ток торговых P&L в качестве образца распределения возможных результатов в следующей сделке. Если привести к текущей цене поток прошлых прибылей и убытков, то мы сможем получить более правдоподобное распределение потенциальных прибылей и убытков для следующей сделки. Таким образом, нам следует рассчитывать оптимальное f из этого измененного распределения прибылей и убытков. Это не означает, что, используя оптимальное f, рассчитанное на основе приведенных данных, мы выиграем больше. Как видно из следующего примера, все выглядит несколько иначе:

Однако если бы все сделки были рассчитаны на основе текущей цены (скажем, 100 долларов за акцию), приведенное оптимальное f позволило бы выиграть больше, чем необработанное оптимальное f.
Что лучше использовать? Следует ли нам определять оптимальное f (и его побочные продукты) на основе приведенных данных или лучше действовать обычным способом? Это больше вопрос ваших предпочтений. Все зависит от того, что более важно в инструменте, которым вы торгуете: процентные изменения или абсолютные изменения. Будет ли движение в 2 доллара по акции в 20 долларов то же, что и движение в 10 долларов по акции в 100 долларов? Посмотрим, например, на торги по доллару и немецкой марке. Будет ли движение в 0,30 пункта при 0,4500 то же, что и движение в 0,40 пункта при 0,6000? На мой взгляд, лучше использовать приведенные данные. С этим, однако, можно поспорить. Например, если акция с 20 долларов выросла до 100 долларов, и мы хотим определить оптимальное f, нам, возможно, потребуется использовать только текущие данные. Сделки, которые происходили при цене в 20 долларов за акцию, относятся к рынку, значительно отличающемуся от существующего в настоящий момент.
Лучше не использовать данные, когда базовый инструмент был на совершенно другом ценовом уровне, так как состояние рынка могло существенно измениться В этом смысле оптимальное f на основе необработанных данных и оптимальное f, получаемое из приведенных данных, будут почти идентичны, когда все сделки происходят при ценах, близких к текущей цене базового инструмента.
Если действительно большое значение имеет то обстоятельство, приводите вы данные или нет, значит вы используете слишком много исторических данных. На самом деле, нет большой разницы, используете ли вы приведенные или необработанные данные, если нет вышеописанной проблемы, поэтому следует пользоваться приведенными данными. Это не означает, что оптимальное f, рас- считанное из приведенных данных, было оптимальным в прошлом. Оно могло таковым и не быть. Оптимальное f, рассчитанное из необработанных данных, могло быть оптимальным в прошлом. Однако оптимальное f, рассчитанное из приведенных данных, имеет больше смысла, так как приведенные данные являются более справедливым представлением распределения возможных результатов по следующей сделке.
Уравнения с (2. 10а) по (2. 10в) дают разные ответы в зависимости от того, какая была открыта позиция: длинная или короткая. Например, если акция куплена за 80, а продана за 100, выигрыш составит 25%. Однако если акция продана по 100, а закрыта по 80, то выигрыш составит только 20%. В обоих случаях позицию открыли по 80 и закрыли по 100. Таким образом, последовательность — хронология трансакций — должна приниматься во внимание. Так как хронология трансакций затрагивает распределение процентных выигрышей и проигрышей, мы допускаем, что будущая хронология скорее всего будет подобна прошлой. Конечно, мы можем игнорировать хронологию сделок (используя 2.10в для длинных позиций и цену выхода в знаменателе 2.10в для коротких позиций), но это означало бы уменьшение информации в исторических данных. Более того, риск торговли является функцией хронологии торговли, и этот факт мы были бы вынуждены игнорировать.
Оптимальное f даст наибольший геометрический рост при большом количестве сделок. Это математический факт. Рассмотрим гипотетический поток сделок:
+3, -3, +10, -5
Из этого потока сделок мы найдем, что оптимальное f= 0,17 (ставка 1 единицы на каждые 29,41 доллара на балансе). Такой подход при данном потоке даст нам наи-больший рост счета.
Представьте себе, что этот поток выражает прибыли и убытки при торговле одной акцией. Оптимально следует покупать одну акцию на каждые 29,41 доллара на балансе счета, несмотря на текущую цену акции. Предположим, что текущая цена акции равна 100 долларам. Более того, допустим, что при первых двух сделках акция стоила 20 долларов, а при двух последних сделках — 50 долларов.
Для наших первых двух сделок, которые произошли при цене акции в 20 долларов, выигрыш в 2 доллара соответствует выигрышу в 10%, а проигрыш 3 долларов соответствует проигрышу в 15%. Для двух последних сделок при цене акции 50 долларов выигрыш 10 долларов соответствует выигрышу в 20%, а проигрыш в 5 долларов соответствует проигрышу в 10%.
1 Разумный подход требует, чтобы мы использовали наибольший проигрыш, по крайней мере, такой же величины, как и в прошлом. С течением времени мы получаем все большее количество данных и большие периоды проигрышей. Например, если бросить монету 100 раз, она может 12 раз подряд выпасть на обратную сторону. Если бросить ее 1000 раз, то, вероятно, можно получить еще больший период, когда монета выпадет обратной стороной. Тот же принцип работает и в торговле. Мы не только должны ожидать более длинные полосы проигрышных сделок в будущем, следует также ожидать большую проигрышную сделку наихудшего случая.

Формулы преобразования необработанных торговых P&L в процент выигрыша и проигрыша для длинных и коротких позиций следующие:
(2. 10а) P&L% = Цена выхода / Цена входа — 1 (для длинных)
(2.106) , P&L% = Цена входа / Цена выхода - 1 (для коротких),
или мы можем использовать следующую формулу для преобразования как длин- ных, так и коротких:
(2.10в) P&L% = P&L в пунктах / Цена входа
Таким образом, для наших 4 гипотетических сделок мы получим следующий поток процентных выигрышей и проигрышей (с точки зрения длинных позиций):
+0,1 ; -0,15 ; +0,2 ; -0,1
Мы назовем этот новый поток преобразованных P&L приведенными данными, так как при торговле они приводятся к цене базового инструмента.
Чтобы учесть комиссионные и проскальзывание, вы должны уменьшить цену выхода в уравнении (2.10а) на сумму комиссионных и проскальзывания. Таким же образом вам следует увеличить цену выхода в (2.106). Если вы используете (2.10в), то должны вычесть сумму комиссионных и проскальзывания (в пунктах) из числителя (P&L в пунктах). Затем мы определим оптимальное f по этим процентным выигрышам и проигрышам. Оптимальное f будет равно 0,09. Преобразуем это оптимальное f= 0,09 в денежный эквивалент, основываясь на текущей цене акции, с помощью формулы:
(2.11) f$ = Наибольший процентный проигрыш * Текущая цена * ($ за пункт/ -f)
Таким образом, так как наш наибольший процентный проигрыш был -0,15, теку- щая цена равна 100 долларам за акцию, а количество долларов на пункт равно 1 (так как мы имеем дело с покупкой только 1 акции), можно определить f$ следую- щим образом:
f$ =-0,15*100*1/-0,09 =-15/-0,09 = 166,67
Следует покупать 1 акцию на каждые 166,67 долларов баланса счета. Если бы мы выбрали 100 акций в качестве единицы, единственной переменной, затронутой этим изменением, было бы количество долларов за полный пункт, которое стало бы равно 100. В результате, f$ было бы 16 666,67 доллара баланса на каждые 100 акций.
Теперь допустим, что цена акции упала до 3 долларов. Наше уравнение для f$ будет таким же, но текущая станет равна 3. Таким образом, сумма для финансиро- вания 1 акции изменится:
f$=-0,15*3* 1/-0,09 = -0,45 / -0,09=5
Теперь следует покупать 1 акцию на каждые 5 долларов баланса счета.
Отметьте, что оптимальное f не изменяется с текущей ценой акции. Оно оста- ется на уровне 0,09. Однако f$ меняется постоянно, так как меняется цена акции. Это не означает, что вы должны обязательно изменить позицию, которую уже открыли в этот день, но если бы вы так поступили, то это пошло бы на пользу тор- говле. Например, если вы открываете длинную позицию по какой-либо акции и ее цена падает, количество денег, которое вам следует разместить под 1 единицу (100 акций в этом случае), также уменьшится (если оптимальное f получено из приведенньк данных). Если ваше оптимальное f получено из необработанных данных, то количество денег, необходимое для 1 единицы, не уменьшится. В обоих случаях ваш дневной баланс понижается. Использование приведенного оптимального f делает более вероятным, что ежедневное изменение размера позиции пойдет вам на пользу Использование приведенных данных для оптимального f неизбежно влечет за собой изменение побочных продуктов1. Мы знаем, что и оптимальное f, и среднее геометрическое (и отсюда TWR) изменятся. Средняя арифметическая сделка также изменится, потому что все сделки в прошлом должны быть пересчитаны, как если бы они происходили при текущей цене. Таким образом, в нашем предполагаемом потоке результатов по 1 акции (+2,-3,+10и-5) мы получим среднюю сделку, равную 1 доллару. Когда мы используем процентные выигрыши и проигрыши (+0,1; -0,15; +0,2 и -0,1), то получаем среднюю сделку (в процентах) +0,5. При цене 100 долларов за акцию мы получим среднюю сделку 100 * 0,05, или 5 долларов за сделку. При цене 3 доллара за акцию средняя сделка становится равной 0,15 доллара (3 * 0,05).
Средняя геометрическая сделка также изменится. Вспомните уравнение (1.14) для средней геометрической сделки:
(1.14) GAT = G * (Наибольший проигрыш /-f),
где G = (среднее геометрическое) -1;
f=оптимальная фиксированная доля. (Разумеется, наш наибольший проигрыш
всегда является отрицательным числом.) Это уравнение эквивалентно следующему:
GAT = (среднее геометрическое - 1) * f$
Мы получили новое среднее геометрическое на основе приведенных данных. Переменная f$, которая была постоянной, когда прошлые данные не приводились, теперь изменится, так как она является функцией текущей цены. Таким образом, наша средняя геометрическая сделка меняется, когда меняется цена базового инструмента.
Порог геометрической торговли также должен измениться. Вспомните уравнение (2.02) для порога геометрической торговли:
где Т = порог геометрической торговли;
ААТ = средняя арифметическая сделка;
GAT =средняя геометрическая сделка;
f= оптимальное f (от 0 до 1). Это уравнение также можно переписать
следующим образом:
Т = ААТ/GAT* f$
Наконец, при сведении в единый портфель нескольких рыночных систем мы дол- жны рассчитать ежедневные HPR. Это также функция f$:
1 Уравнения риска разорения, хотя они напрямую и не упомянуты в этой книге, должны также изменяться при использовании приведенных данных. Вообще в качестве вводных данных для уравнений риска разорения используют необработанные данные P&L. Однако когда вы используете приведенные данные, новый поток процентных выигрышей и проигрышей должен умножаться на текущую цену базового инструмента, и далее надо использовать именно этот получившийся поток. Таким образом, при текущей цене инструмента 100 долларов поток процентных выигрышей и проигрышей 0,1; -0,15; 0,2; -0,1 преобразуется в поток 10; -15; 20; -10. Этот новый поток и следует использовать для уравнений риска разорения.

(2.12) Дневное HPR = D$ / f$ + 1,
где D$ = долларовое изменение цены 1 единицы по сравнению с прошлым днем, т. е. (закрытие сегодня - закрытие вчера) * (доллары за пункт);
f$= текущее оптимальное f в долларах, рассчитанное из уравнения (2.11). Здесь текущей ценой является закрытие последнего дня.
Предположим, некая акция сегодня вечером закрылась на уровне 99 долларов. На прошлой сессии ее цена была 102 доллара. Наибольший процентный проигрыш равен -15. Если f= 0,09, тогда f$ равно:
f$ =-0,15*102*1/-0,09 =-15,3/-0,09 = 170
Так как мы имеем дело только с одной акцией, цена одного пункта составляет 1 доллар. Мы можем теперь определить сегодняшнее дневное HPR из уравнения (2.12):
(2.12) Дневное HPR = (99 -102) * 1 / 170 + 1 =-3/170+1 = -0,01764705882 + 1 = 0,9823529412
Теперь вернемся к началу нашей дискуссии. При потоке торговых P&L оптимальное f позволит получить наибольший геометрический рост (при условии, что арифметическое математическое ожидание положительное)'. Мы используем по- ток торговых P&L в качестве образца распределения возможных результатов в следующей сделке. Если привести к текущей цене поток прошлых прибылей и убытков, то мы сможем получить более правдоподобное распределение потенциальных прибылей и убытков для следующей сделки. Таким образом, нам следует рассчитывать оптимальное f из этого измененного распределения прибылей и убытков. Это не означает, что, используя оптимальное f, рассчитанное на основе приведенных данных, мы выиграем больше. Как видно из следующего примера, все выглядит несколько иначе:
Однако если бы все сделки были рассчитаны на основе текущей цены (скажем, 100 долларов за акцию), приведенное оптимальное f позволило бы выиграть больше, чем необработанное оптимальное f.
Что лучше использовать? Следует ли нам определять оптимальное f (и его побочные продукты) на основе приведенных данных или лучше действовать обычным способом? Это больше вопрос ваших предпочтений. Все зависит от того, что более важно в инструменте, которым вы торгуете: процентные изменения или абсолютные изменения. Будет ли движение в 2 доллара по акции в 20 долларов то же, что и движение в 10 долларов по акции в 100 долларов? Посмотрим, например, на торги по доллару и немецкой марке. Будет ли движение в 0,30 пункта при 0,4500 то же, что и движение в 0,40 пункта при 0,6000? На мой взгляд, лучше использовать приведенные данные. С этим, однако, можно поспорить. Например, если акция с 20 долларов выросла до 100 долларов, и мы хотим определить оптимальное f, нам, возможно, потребуется использовать только текущие данные. Сделки, которые происходили при цене в 20 долларов за акцию, относятся к рынку, значительно отличающемуся от существующего в настоящий момент.
Лучше не использовать данные, когда базовый инструмент был на совершенно другом ценовом уровне, так как состояние рынка могло существенно измениться В этом смысле оптимальное f на основе необработанных данных и оптимальное f, получаемое из приведенных данных, будут почти идентичны, когда все сделки происходят при ценах, близких к текущей цене базового инструмента.
Если действительно большое значение имеет то обстоятельство, приводите вы данные или нет, значит вы используете слишком много исторических данных. На самом деле, нет большой разницы, используете ли вы приведенные или необработанные данные, если нет вышеописанной проблемы, поэтому следует пользоваться приведенными данными. Это не означает, что оптимальное f, рас- считанное из приведенных данных, было оптимальным в прошлом. Оно могло таковым и не быть. Оптимальное f, рассчитанное из необработанных данных, могло быть оптимальным в прошлом. Однако оптимальное f, рассчитанное из приведенных данных, имеет больше смысла, так как приведенные данные являются более справедливым представлением распределения возможных результатов по следующей сделке.
Уравнения с (2. 10а) по (2. 10в) дают разные ответы в зависимости от того, какая была открыта позиция: длинная или короткая. Например, если акция куплена за 80, а продана за 100, выигрыш составит 25%. Однако если акция продана по 100, а закрыта по 80, то выигрыш составит только 20%. В обоих случаях позицию открыли по 80 и закрыли по 100. Таким образом, последовательность — хронология трансакций — должна приниматься во внимание. Так как хронология трансакций затрагивает распределение процентных выигрышей и проигрышей, мы допускаем, что будущая хронология скорее всего будет подобна прошлой. Конечно, мы можем игнорировать хронологию сделок (используя 2.10в для длинных позиций и цену выхода в знаменателе 2.10в для коротких позиций), но это означало бы уменьшение информации в исторических данных. Более того, риск торговли является функцией хронологии торговли, и этот факт мы были бы вынуждены игнорировать.